Homa
Table of Contents
- Introduction
- Data Center Environment
- Message vs Packet
- Problems with TCP
- Sender vs Receiver
- Packet Types
- Features
- Design Principles
- Linux Internals
- Streaming vs Messages
- API
- Message Sequence Scenarios
- Algorithms
- Resources
Introduction
- The Transmission Control Protocol (TCP) is the most widely used transport protocol on the internet. It is well-designed, but just like any other protocol, it has its own issues. It is not suitable for every environment and faces problems in a Data Center environment.
- Homa is transport protocol designed for the Data Centers. It aims to replace TCP as the transport protocol in Data Centers and claims to fix all of TCP’s problems for the Data Center. It is not API-compatible with TCP.
- Homa reduces the ‘Data Center tax’ that TCP introduces with its connection maintenance and processing overheads.
- The primary goal of Homa is to provide the lowest possible latency for short messages at high network load.
- The focus is on reducing tail message latency (P99 [99th percentile] latency) for short messages, i.e., the latency of short messages at high network load, as it is the most important performance metric for Data Center applications.
Data Center Environment
Topology
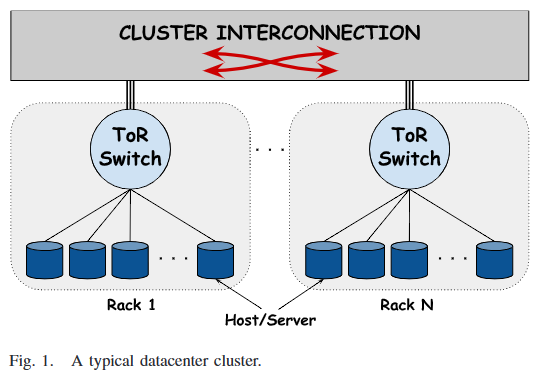
- Data Center -> Clusters -> Racks (with a Top of Rack [ToR] switch) -> Machines
- There are multiple structures in which connections can be made between each of the components above, but the usual structure is as he above point.
- Common topologies
- Fat-Tree
- Leaf-Spine (or Spine-and-Leaf)
- VL2
- JellyFish
- DCell
- BCube
- Xpander
Traffic Properties
- It is difficult to generalise all Data Center traffic into one certain type, because it is highly dependent on how applications are designed and built.
- Depending on the application, there can be thousands of flow arrivals per second.
- Flows are unpredictable in types, sizes and burst periods.
- Burstiness can be in terms of traffic in a flow or the number of flows.
- Connections can be long-lived as well and need not always be transmitting.
- Rough types
- Interactive flows/latency-sensitive flows
- Throughput-sensitive flows
- Deadline-bound flows
- Usually, short flows require low latencies and long flows require high throughput.
Traffic Control Challenges
- Unpredictable traffic matrix
- Application dependent
- Most flows are short with just a few packets, but most bytes are delivered by long flows.
- High flow arrival rates with majority being short flows.
- Mix of various flow types/sizes
- Application dependent
- Interactive flows (User-initiated queries like web searches) are time-sensitive, latency-sensitive and high priority flows.
- Throughput-sensitive flows (like MapReduce parallel data computing jobs) are not delay-sensitive, but need consistent bandwidth.
- Deadline-bound flows with soft or hard deadlines can be both Interactive or Throughput-sensitive flows.
- Traffic burstiness
- Traffic burstiness causes increased packet losses, increased buffer occupancy, increased queuing delay, decreased throughput, increased flow completion times
- TCP Slow Start with large window sizes can cause bursty traffic as well.
- Packer re-ordering
- At the receiver: Increases latency, Increases CPU utlization and reduces the server’s link utilization
- Features such as Fast Retransmit might mistake re-ordering for loss.
- Performance Isolation
- Control has to be developed on multiple layers and on multiple hardware components to prevent misuse and privacy, while keeping Service Level Agreements (SLAs) in mind.
- The Incast problem
- Multiple senders sending to one machine causes bottleneck issues.
- The Outcast problem
- TCP Outcast is when a port that has many flows and a few flows coming in from different ports, gives priority to the port with many flows, causing Port Blackout for the port with fewer flows. Port Blackout is essentially packets of the fewer flows being dropped, which affects them due to the TCP timeouts it causes.
Network Requirements
A Data Center environment should have:
- Very high bandwidth/capacity/link utilization
- Depends on topology and traffic control measures.
- Aids in having more tenants on the same infrastructure.
- Very low latency
- Very small flow completion times
- Mainly affected by queuing and packet losses.
- Very low deadline miss rate/lateness
- High fairness
- Applies to shared resources like link bandwidth and buffer space. (Maybe even to CPU cycles and memory.)
- SLAs should always be met.
- Prevents misuse and starvation.
- High energy efficiency
Protocol Requirements
Some of the important features a Data Center transport protocol should have:
- Reliable delivery
- Data should be delivered regardless of failures.
- Low latency
- Data should be delivered as fast as possible.
- Tail latency should be good.
- Packet processing overheads should be low.
- High throughput
- Both data throughput (amount of data sent) and message throughput (no. of messages sent) should be high.
- Congestion control
- Refers to packet buildup in core and edge buffers.
- Congestion needs to be kept at a minimum to ensure low latency.
- Efficient Load Balancing
- Trying to load balance Data Center workloads causes additional overheads to manage cache and the connections, and also causes hot spots where workload is not properly distributed.
- Load Balancing overheads are a major reason for tail latency.
- Network Interface Card/Controller (NIC) offload
- The protocol cannot be a pure software implementation, because that’s too slow. It should make use of inherent NIC features, for which better NICs are needed as well.
Message vs Packet
- Message
- A logically sensible data unit that makes sense in its entirety and can be processed.
- Packet
- A split of a message (a chunk) that obviously doesn’t make logical sense individually, but can be combined with other packets to form a message.
- They usually have offsets, sequence numbers, or some other mechanism to help order packets in a logical sequence.
Problems with TCP
The following features of TCP cause it problems in the Data Center:
Stream Orientation
- TCP is a stream-oriented protocol. It blindly sends how much ever data that the layer above it in the network stack gives it, without having any knowledge of a logical chunk of data.
- Please refer to the ‘Streaming vs Messages’ section.
Connection Orientation
- TCP is a connection-oriented protocol. There is a three-way handshake that takes place to establish a connection between a client and a server.
- Connections are not the best inside the Data Center, because each application might have hundreds or thousands of them and that causes overheads in space and time.
- Techniques such as Delayed ACKs have to be used to reduce packet overheads.
- Keeping aside packet buffer space and application level state, 2000 bytes of state data has to be maintained for every TCP socket.
- Connection setup takes up one Round Trip Time (RTT).
Fair scheduling
- TCP uses Fair Scheduling to do bandwidth sharing between various connections.
- Under high loads, short messages have a very bad RTT as compared to long messages, due to TCP Head of Line Blocking (HoLB).
- Under high load, all streams share bandwidth, which collectively slows down everyone.
Sender-Driven Congestion Control
- In TCP, the sender tries to avoid congestion.
- Congestion is usually detected when there is buffer occupancy, which implies that there will be some packet queuing, which further implies increased latency and HoLB.
- TCP does not make use of priority queues in modern switches, which implies that all messages are treated equally, which causes problems for short messages behind long message queues. (HoLB)
- It causes a latency vs throughput dilemma, where less latency implies buffers being under-utilized, which in-turn reduces the throughput for long messages, and high throughput implies always having data in buffers ready to go, but the queuing causes delays for short messages, increasing the latency.
- Please refer to the ‘Streaming vs Messages’ section.
In-Order Packet Delivery
- In comparison to Homa, TCP has a lower out-of-order packet tolerance and prefers that packets are sent in-order and on the same link (Flow-consistent Routing).
- Asymmetries in packet delivery in a Data Center environment due to Packet Spraying (sending packets across multiple connections) can cause packet reordering beyond TCP’s tolerance threshold and cause unnecessary retransmissions.
- If Packet Spraying is not used and Flow-consistent Routing is used, which fixes links for particular TCP flows, it can cause hot spots for the duration of the connection on particular links if multiple flows get hashed through the same links.
- Linux performs Load Balancing at the software level by routing packets through multiple cores for processing and to maintain the order or delivery, all packets have to pass through the same sequence of cores, which can lead to core hot spots as well, if multiple flows get hashed to the same cores. This also increases the tail latency of TCP.
Sender vs Receiver
- Client to server communication:
- Sender: Client
- Receiver: Server
- Server to client communication:
- Sender: Server
- Receiver: Client
A peer can be a sender or a receiver and can have multiple RPCs.
Packet Types
NOTE:
Homa’s packet types:
DATA
DATA(rpc_id, data, offset, self_prio, m_len)- Sent by the sender.
- Contains a contiguous range of bytes within a message, defined by an offset.
- Also indicates the total message length.
- It has the ability to acknowledge (
ACK) one RPC, so future RPCs can be used to acknowledge one RPC, thus not requiring an explicitACKpacket to be sent.
GRANT
GRANT(rpc_id, offset, exp_prio)- Sent by the receiver.
- Indicates that the sender may now transmit all bytes in the message up to a given offset.
- Also specifies the priority level to use for the
DATApackets. - When are
GRANTpackets sent?
RESEND
RESEND(rpc_id, offset, len, exp_prio)- Sent by the sender or receiver.
- Indicates that the sender should re-transmit a given range of bytes within a message.
- Includes priority that should be used for the retransmitted packets.
- To prevent unnecessary bandwidth usage, Homa only issues one outstanding
RESENDpacket to a given peer at a time. (One peer can have multiple RPCs.) Homa rotates theRESENDs among the RPCs to that peer. - If enough timeouts occur (i.e., enough
RESENDpackets are sent), Homa concludes that a peer has crashed, aborts all RPCs for that peer and discards all the state associated with those RPCs.
UNKNOWN
UNKNOWN(rpc_id)- Sent by the sender or receiver.
- Indicates that the RPC for which a packet was received is unknown to it.
BUSY
BUSY(rpc_id)- Sent by the sender.
- Indicates that a response to
RESENDwill be delayed.- The sender might be busy transmitting higher priority messages or another RPC operation is still being executed.
- Used to prevent timeouts.
- It can be thought of as a ‘keep-alive’ indicator, as it keeps the communication alive and prevents the RPC from being aborted due to lack of data receipt.
CUTOFFS
CUTOFFS(rpc_id, exp_unsched_prio)- Sent by the receiver.
- Indicates priority values that the sender should use for unscheduled packets.
- When are
CUTOFFSpackets sent?
ACK
ACK(rpc_id)- Sent by the sender.
- Explicitly acknowledges the receipt of a response message to one or more RPCs.
- Aids the receiver to discard state for completed RPCs.
NEED_ACK
NEED_ACK(rpc_id)- Sent by the receiver.
- Indicates an explicit requirement for an acknowledgement (
ACKpacket) for the response of a particular RPC.
FREEZE
- Only for performance measurements, testing and debugging.
BOGUS
- Only for unit testing.
Features
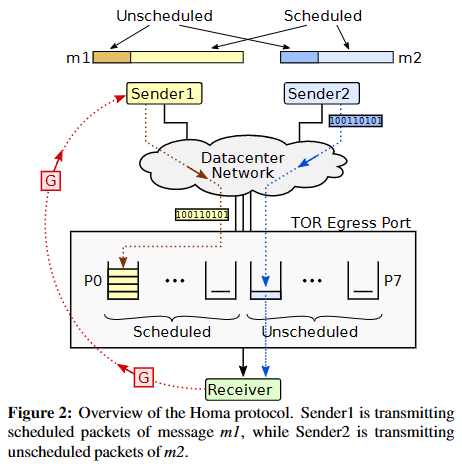
Homa’s features:
Message Orientation
- Homa is a Message-oriented protocol, that implements Remote Procedure Calls (RPCs) rather than streams.
- Please refer to the Message vs Packet and the Streaming vs Messages sections.
- Homa exposes discrete messages to transport, letting multiple threads read from a single socket without worrying about getting a message from a different connection (as in the TCP world, especially with HTTP/2 multiplexing multiple streams on one TCP connection, causing HoLB).
Connectionless Protocol
- Homa uses RPCs and so it doesn’t require explicit connection establishment between the sender and receiver, and vice versa. This reduces connection setup overhead.
- An application can use a single socket to manage any number of concurrent RPCs with any number of peers.
- Each RPC is handled independently and there are no message ordering guarantees between concurrent RPCs.
- Homa ensures reliable connections (errors are sent after unrecoverable network or host failures).
- It is a connectionless protocol, but not a stateless protocol.
- State maintained by Homa
- State for sockets, RPCs and peers are kept (200 bytes per host vs TCP’s 2000 bytes per connection [not including data buffer space]).
- One way to think of Homa is that it maintains short-lived and lightweight connections for each RPC.
- Each RPC is handled independently and Flow Control, Retry and Congestion Control are implemented per RPC state.
SRPT
- Homa uses Shortest Remaining Processing Time (SRPT) Scheduling rather than TCP’s Fair Scheduling.
- Homa uses SRPT Scheduling (a type of Run-to-Completion Scheduling) to queue messages to send and receive. It is best if both, the receiver and the sender, use SRPT, as it prevents short messages from starving behind long messages in queues on both ends.
- Homa makes use of priority queues in modern switches and queues shorter messages through the priority queues, so that they don’t get starved by long messages. This helps reduce the ‘latency vs bandwidth’ optimization problem.
- Priority is divided into two groups, the highest levels are for unscheduled packets and the lower levels are for scheduled packets. In each group, the highest priorities are for the shorter messages.
- All packet types other than
DATApackets have the highest priorities.
- All packet types other than
- The receiver assigns priorities dynamically (depending on the flows that it has) and can change them at any time it wishes. It communicates them through
GRANTpackets for scheduled packets and throughCUTOFFSpackets for unscheduled packets. - The receiver assigning priorities makes sense because it knows all the flows that want to send data to it and its current network load and buffer occupancy.
- Reducing queuing is the key to reducing latency.
- Homa not only limits queue buildup in switches, but also in the Network Interface Controller (NIC), so that HoLB does not take place.
- To prevent queue build up in the NIC, it uses a queue and a ‘Pacer Thread’ that essentially keeps an approximate of the time in which the NIC queue will be empty and sends packets to the NIC from its queue based on that estimate while maintaining the original SRPT order.
- Homa not only limits queue buildup in switches, but also in the Network Interface Controller (NIC), so that HoLB does not take place.
- Homa intentionally does ‘controlled overcommitment’, i.e., it allows a little buffering (for longer messages), to keep link utilization high (thus optimizing for throughput, while keeping latency low through SRPT and priority queues).
- The controlled overcommitment helps in keeping up capacity utilization in cases where senders aren’t sending messages in a timely fashion.
- Priority is divided into two groups, the highest levels are for unscheduled packets and the lower levels are for scheduled packets. In each group, the highest priorities are for the shorter messages.
- Homa also allocates 5-10% of the bandwidth to the oldest message (which will be the longest one), so that the longest message also doesn’t completely starve. Both, the granting mechanism and the Pacer Thread take this into consideration.
Receiver-Driven Congestion Control
- A receiver is usually in a better position to signal and drive congestion rather than the sender, because the receiver knows how much buffer capacity it has left and the number of RPCs that it has. So, it is better to let the receiver signal whether messages can be sent or not.
- A sender can send a few unscheduled packets to receive some replies from the receiver to test the waters, but packets after that will be scheduled and can be sent only if the receiver sends a grant for those messages.
- The message size is mentioned in the initial unscheduled blindly sent (to reduce latency) packets, which further helps the receiver to make a decision on scheduling those messages and also allows it to give priority to shorter messages.
- Yes, this might cause some buffering if there are too many senders that send unscheduled packets, but that minimum buffering is unavoidable. The scheduling of further messages through the grant mechanism ensures reduced buffer occupancy.
- A
GRANTpacket is sent after a decided amount of data (defaulted at 10,000 bytes), if the receiver decides that it can accept more data and it contains an offset for the number of outstanding bytes of the message size that it wants from the sender and also the priority that the sender should send the packet with. So Homa can vary priorities dynamically based on the load it has on the receiver.- Homa does not send a
GRANTpacket for everyDATApacket, as that causes a lot of overheads and Homa uses TCP Segmentation Offload (TSO), which implies that the sender transmits packets in groups, so every packet does not need to have aGRANTpacket.- The ‘RTT bytes’ that the
GRANTpacket sends might be split into multiple packets depending on the Maximum Transmission Unit (MTU) value.
- The ‘RTT bytes’ that the
- Homa does not send a
- The sender should transmit ‘RTT bytes’ (including software delays on both ends) and by the time RTT bytes are sent, it should receive an indication from the receiver whether to keep sending or not, thus reducing transmission latency in case an immediate grant is received.
- The message size is mentioned in the initial unscheduled blindly sent (to reduce latency) packets, which further helps the receiver to make a decision on scheduling those messages and also allows it to give priority to shorter messages.
- As the receiver knows the load it has and expects from the received messages, it can prioritise messages (using a small number of priority queues) and the bandwidth they can have.
- Knowing the message sizes, they can predict the bandwidth required and take the decision of granting and priority on those basis.
- This helps the receiver implement SRPT Scheduling, as they have the priority in their control.
Out-of-Order Packet Tolerance
- Homa has a high tolerance for out-of-order packets.
- Homa can tolerate Out-of-Order packets, so Packet Spraying works, which aids load balancing over multiple links, avoiding network traffic hot spot creation.
- Homa does not follow TCP’s Flow Consistent Routing.
No Per-Packet Acknowledgements
- Homa does not send out explicit acknowledgements for every packet, thus reducing almost half the packets that have to be sent per message. This reduces transmission overheads and conserves bandwidth.
- As mentioned in the ‘Homa Features’ sub-point ‘Receiver-driven Congestion Control’ above, a
GRANTpacket is not sent for everyDATApacket, but for a bunch of packets, soGRANTpackets are not acknowledgement packets for every packet that was sent.- Although not explicitly mentioned anywhere, they can be considered as SACK (Selective Acknowledgement) packets in my opinion.
- If any packet is missing, the receiver will send a
RESENDpacket requesting for the information. - The sender has to send an explicit
ACKpacket on completely receiving a RPC response message from the receiver for a RPC request message, so that the receiver can discard the RPC state.- If an
ACKpacket is not sent by the sender, the receiver can explicitly ask for one using theNEED_ACKpacket. - If the sender has not received the entire response message, it can send a
RESENDpacket to the receiver.
- If an
At-Least-Once Semantics
- At-least-once semantics
- In case of failures or losses, Homa does have mechanisms to ensure retransmission (Eg: The
RESENDpacket or fresh retries after deadlines), so packets are sent at least once, but can be sent more times to ensure delivery.
Design Principles
Homa’s Design Principles:
- Transmitting short messages blindly
- Using in-network priorities
- Allocating priorities dynamically at receivers in conjunction with receiver-driven rate control
- Controlled over-commitment of receiver downlinks
Linux Internals
How Homa works in Linux:
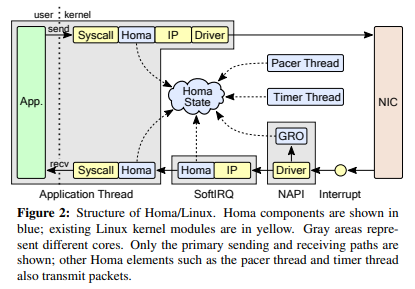
- Transmit (top):
homa_send()-> copy packets -> TSO/GSO -> Homa, IP layer -> NIC (and its driver) - Receive (bottom): NIC (RSS) -> Interrupt -> NAPI (GRO, SoftIRQ core choosing) -> SoftIRQ (network stack traversal) -> copy packets ->
homa_recv() - Research paper explanation: Packet flow and batching (4.1) from A Linux Kernel Implementation of the Homa Transport Protocol (USENIX)
- Review article: A Linux Kernel Implementation of the Homa Transport Protocol, Part II
- Linux-specific details
Streaming vs Messages
NOTE: Message vs Packet
The Problem with TCP Streaming
- TCP is not aware of the message size. It is only aware of the length of the current packet.
- TCP will break up (segment) whatever it receives from the application above it in the OSI stack into packets of ‘Maximum Segment Size (MSS) bytes’ and send it across. (Streaming)
- It might also wait for MSS to be fulfilled before sending (like in Nagle’s Algorithm), but that is a setting that can be toggled.
- does tcp/ip conveys complete messages?
- This streaming behaviour obviously adds buffering and packet ordering at the receiver, but more importantly the receiver has no knowledge of when it can start processing something or how much data it is going to receive. The sender is thus responsible to not overwhelm the receiver (Flow Control) and the network (Congestion Control).
- TCP streaming causes Load Balancing difficulties, because the path of sending data is usually consistent (Flow-consistent routing) and multiple flows on the same paths can cause congestion (hot spots) and HoLB.
- Causes an increase in tail latency due to HoLB, where short messages get delayed behind long messages on the same stream.
- Using multiple TCP connections to the same host to counter HoLB causes a connection explosion, with too much state to be maintained per connection and too much work to send, receive and manage all the connections on the receiver and sender.
How Messages Help
- The sender transmits the message size to the receiver during the initial unscheduled transmission, so the receiver can calculate the exact bandwidth required for the entire communication and decide grants and priorities.
- Buffering and packet ordering at the receiver will still exist here, but now the receiver is cognizant of how much data it can expect to receive and can make decisions based on bandwidth requirements, its current load, its buffer occupancy, observed RTT, etc.
- This helps
GRANTpackets from the receiver to the sender to specify an offset of outstanding ‘RTT bytes’ of the message to transmit to the receiver to ensure as far as possible, no interruptions in transmitting, which improves bandwidth utilization.- Specifying this also helps with buffer occupancy predictions and checks, because the receiver knows how much a particular RPC was allowed to send in a particular packet.
- This puts the power of Congestion and Flow Control in the hands of the receiver, which makes more sense, because it is the entity that has the best knowledge of its state, rather than the sender having to make guesses based on parameters like ‘packet loss’ and ‘duplicate acknowledgements’, that are not the most accurate indicators of congestion.
- This helps
- Removing streaming also gets rid of the TCP Head of Line Blocking (HoLB) problem.
- In the HTTP world, QUIC (the transport protocol for HTTP/3) solves this by having multiple independent streams, unlike TCP in HTTP/2, which was multiplexing multiple streams over a single TCP stream/connection (thus causing HoLB).
- HoLB: Multiple messages multiplexed over a single TCP connection (as in HTTP/2) implies that even if only one packet at the start of the Congestion Window (CWND) needs to be retransmitted, all the packets after it will be buffered at the receiver and not be handed to their respective streams up the networking stack even if the individual packets that might be belonging to different streams are complete.
- This is also where the scare of reading packets from a different stream from one connection pops up in TCP.
- The point here can be that Homa is doing away with streaming altogether and just using messages, so not only is HoLB solved, but so are the other issues with streaming.
- HoLB: Multiple messages multiplexed over a single TCP connection (as in HTTP/2) implies that even if only one packet at the start of the Congestion Window (CWND) needs to be retransmitted, all the packets after it will be buffered at the receiver and not be handed to their respective streams up the networking stack even if the individual packets that might be belonging to different streams are complete.
- In the HTTP world, QUIC (the transport protocol for HTTP/3) solves this by having multiple independent streams, unlike TCP in HTTP/2, which was multiplexing multiple streams over a single TCP stream/connection (thus causing HoLB).
API
NOTE:
- These are the functions that implement the Homa API visible to applications. They are intended to be a part of the user-level run-time library.
- Source:
homa_api.cfile
Homa’s API:
homa_send()- Send a request message to initiate a RPC.
homa_sendv()- Same as
homa_send(), except that the request message can be divided among multiple disjoint chunks of memory.
- Same as
homa_reply()- Send a response message for a RPC previously received.
homa_replyv()- Similar to
homa_reply(), except the response message can be divided among several chunks of memory.
- Similar to
homa_abort()- Terminate the execution of a RPC.
homa_abortp()- Same as
homa_abort(), but just receives all parameters in onestructinstead of separately/individually.
- Same as
Message Sequence Scenarios
NOTE: Sender vs Receiver
Homa’s Message Sequence Scenarios:
Error-Free Communication
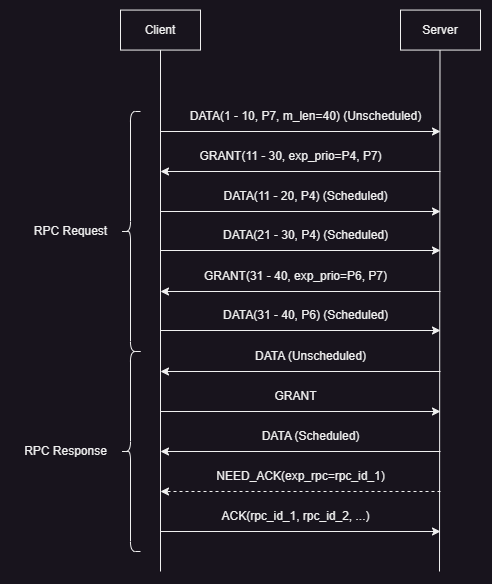
- The image above showcases a normal Homa RPC communication.
- Both, a RPC Request and a RPC Response are shown.
- Priority levels:
P0(lowest) toP7(highest) - It is important to note that
GRANTpackets are for ‘RTT bytes’ to keep link utilization at 100%, butDATApackets are of the size of the Maximum Transmission Unit (MTU). So eachGRANTpacket might generate multipleDATApackets.
Scheduled Data Loss
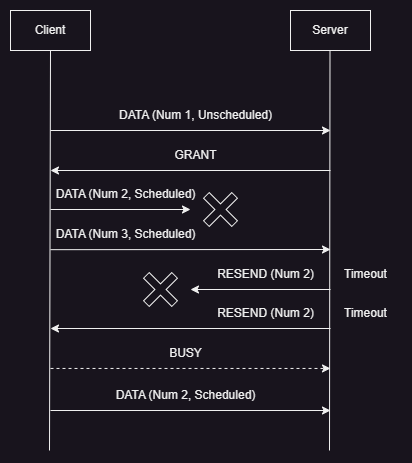
- A RPC Request is shown in the image above.
- Here, a
DATApacket is lost and theRESENDpacket for that missing data is lost as well, but the nextRESENDpacket makes it to the sender. - The sender can either immediately respond with the missing data in a
DATApacket or if it is busy transmitting other higher priority packets, then it can send aBUSYpacket to the receiver to prevent a timeout (like a ‘keep-alive’ indicator) and can send theDATApacket once it is free.
Aborted RPC
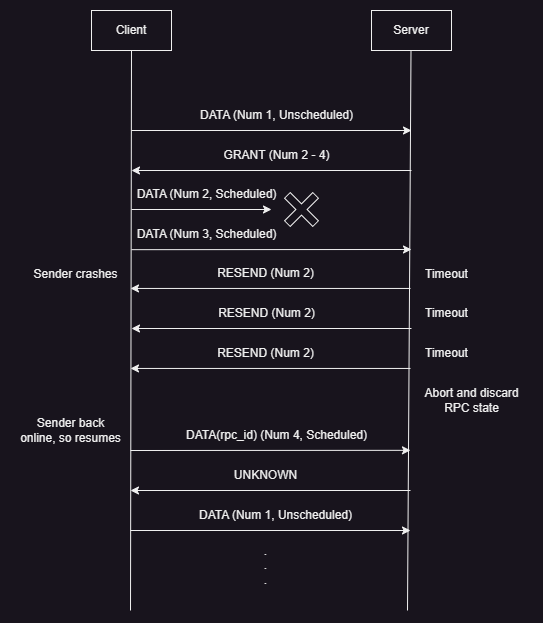
- A RPC Request is shown in the image above.
- The sender crashes after sending two of its three granted
DATApackets. The first granted (scheduled)DATApacket is lost as well, which causes a timeout on the receiver, causing it to send aRESENDpacket for the missing data. - As the sender has crashed, the
RESENDpacket does not get an expectedDATApacket response, which leads to timeouts and moreRESENDpackets. - After multiple
RESENDpackets not receiving responses, the receiver determines that the sender is non-responsive and discards all of the state related to that RPC ID. - On coming back online, the sender looks at its previous state and tries to resume by sending the last granted
DATApacket that it had not sent, but the receiver sends anUNKNOWNpacket, as it has already discarded all information related to that RPC ID. - The sender has to re-start the communication with the receiver.
Unscheduled Data Loss
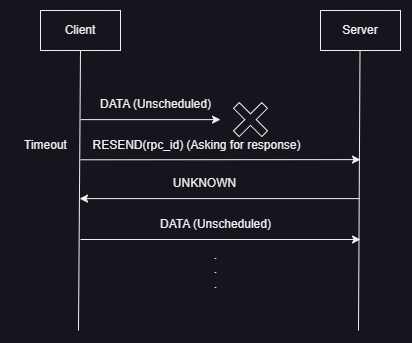
- A RPC Request is shown in the image above.
- This scenario needs to be confirmed properly, but this is most likely how it happens.
- If the blindly sent unscheduled
DATApackets don’t reach the receiver due to loss, overload, congestion or other reasons, then the sender times out waiting for a response from the receiver. - On timing out, the sender sends a
RESENDpacket to the receiver, asking for a response. - If the
RESENDpacket reaches the receiver, then it will respond with anUNKNOWNpacket, because it never got the initial packets and was never aware of the RPC. - The sender has to re-start the communication with the receiver.
Algorithms
Some of the algorithms that Homa implements for
- Sorting Peers and RPCs
- Calculating Scheduled Priorities
- Calculating Unscheduled Priorities
- Calculating
rtt_bytes - Calculating
GRANTOffset - Calculating Unscheduled Bytes Offset
All details as seen in commit
9c9a1ffof the Homa Linux kernel module (31st March 2023).
Sorting RPCs and Peers
-
Constituents
- Peers (
P)- There can be multiple peers (hosts) transmitting (sending (
S)) to the same receiver (R). - Each such peer can be sent
GRANTpackets to send more data.
- There can be multiple peers (hosts) transmitting (sending (
RPCs: Every peer can have multiple RPCs transmitting to the same receiver.
Example:
P1(RPC1, RPC2) -> R1 P2(RPC3) -> R1 P3(RPC4, RPC5, RPC6) -> R1 or S(P1(RPC1, RPC2), P2(RPC3), P3(RPC4, RPC5, RPC6)) -> R1 - Peers (
- A Homa receiver maintains a list of peers (
grantable_peers) that are sending it data and every peer ingrantable_peersmaintains a list of RPCs (grantable_rpcs) that are sending data to that receiver. - The
grantable_rpcslist is sorted based on the number of bytes still to be received (bytes_remaining). The RPC with the leastbytes_remainingis at the head (start) of the list.- If
bytes_remainingare equal, then the time (birth) at which the RPC was added to thegrantable_rpcslist is used to break the tie. The older RPC will be nearer to the head (start) of the list.
- If
- The
grantable_peerslist is also sorted based on thebytes_remainingparameter of the first RPC in each peer’sgrantable_rpcslist. The peer with the leastbytes_remainingin the first RPC of itsgrantable_rpcslist is at the head of thegrantable_peerslist.- To break a
bytes_remainingtie, the samebirthfactor as mentioned in the sub-point above is responsible.
- To break a
- RPCs per peer are ordered first and then peers are ordered.
- When are RPCs and peers sorted?
Algorithm
/* - The overall Homa state maintains one sorted grantable peer list (`homa_state->grantable_peers`).
* - Every peer in that list maintains a sorted grantable RPC list (`peer->grantable_rpcs`).
* - The algorithm below first sorts a RPC in its peer's `grantable_rpcs` list and then due to that change, sorts that peer in the `grantable_peers` list.
* - Logic derived from https://github.com/PlatformLab/HomaModule/blob/9c9a1ff3cbd018810f9fc11ca404c5d20ed10c3b/homa_incoming.c#L819-L933
*/
position_rpc(homa_state, rpc_to_check) {
peer_to_check = rpc_to_check->peer;
while(rpc in peer_to_check->grantable_rpcs) {
if(rpc->bytes_remaining > rpc_to_check->bytes_remaining) { // RPC with fewest bytes wins.
// Add `rpc_to_check` before `rpc`.
// Due to above change, `peer_to_check` might have to be re-positioned in `homa_state->grantable_peers`.
position_peer(homa_state, peer_to_check);
break;
}
else if(rpc->bytes_remaining == rpc_to_check->bytes_remaining) {
if(rpc->birth > rpc_to_check->birth) { // Tie breaker: Oldest RPC wins.
// Add `rpc_to_check` before `rpc`.
// Due to above change, `peer_to_check` might have to be re-positioned in `homa_state->grantable_peers`.
position_peer(homa_state, peer_to_check);
break;
}
}
}
}
position_peer(homa_state, peer_to_check) {
first_rpc_in_peer_to_check = get_list_head(peer_to_check);
while(peer in homa_state->grantable_peers) {
first_rpc_in_peer = get_list_head(peer);
if(first_rpc_in_peer->bytes_remaining > first_rpc_in_peer_to_check->bytes_remaining) { // Peer having first RPC with fewest bytes wins.
// Add `peer_to_check` before `peer`.
break;
}
else if(first_rpc_in_peer->bytes_remaining == first_rpc_in_peer_to_check->bytes_remaining) {
if(first_rpc_in_peer->birth > first_rpc_in_peer_to_check->birth) { // Tie breaker: Peer with oldest first RPC wins.
// Add `peer_to_check` before `peer`.
break;
}
}
}
}
RPC and Peer Sorting Timing
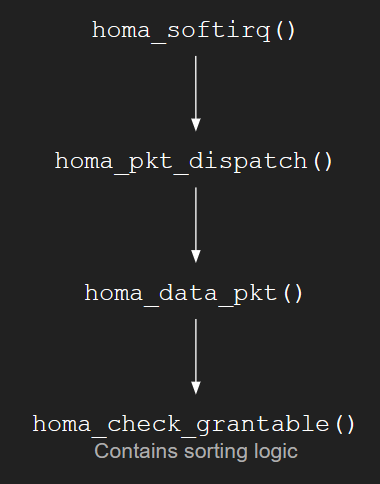
- The sorting of RPCs and peers happens in the
homa_check_grantablefunction. - The
homa_check_grantablefunction is called by thehoma_data_pktfunction (which handles incomingDATApackets), if the incoming message had scheduled bytes in it. - The
homa_data_pktfunction is called by thehoma_pkt_dispatchfunction that handles all incoming packets. - The
homa_pkt_dispatchfunction is called by thehoma_softirqfunction that handles incoming packets at the SoftIRQ level in the Linux Kernel. (SoftIRQ: 1 and 2)
Calculating Scheduled Priorities
- A Homa receiver sends
GRANTpackets to senders to give them permission to sendDATApackets to it. ThoseGRANTpackets have apriorityfield in them, which the sender has to add to theDATApackets they send.- The first RPC in the
grantable_rpcslist in every peer is granted and it is given its own scheduled data priority after calculations.
- The first RPC in the
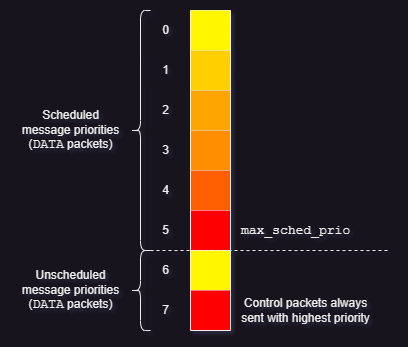
- Homa’s default priority range is from
0to7(eight levels) (Source). Level0has the lowest priority while level7has the highest priority.- The levels are manually split in two parts (by
max_sched_prio), the former for scheduled packets and the latter for unscheduled packets.- The former part that is for scheduled packets always has the lower priorities of the entire range.
- The latter part (highest priorities in the entire range) is always kept for the unscheduled packets, as they always have the highest priority.
- Example (as seen in picture above): If priority levels are from
0(lowest) to7(highest) andmax_sched_priois5, then scheduled packets can have priorities between0and5(both inclusive), while unscheduled packets can have priorities6and7. - The
max_sched_prioparameter is set using theunsched_cutoffsarray.
- In each half of the range, Homa tries to assign the lowest possible priority to each RPC, so that newer messages with higher priorities can be accommodated easily to implement SRPT properly.
- The levels are manually split in two parts (by
- When are offsets and scheduled priorities calculated?
Algorithm
// Logic derived from https://github.com/PlatformLab/HomaModule/blob/9c9a1ff3cbd018810f9fc11ca404c5d20ed10c3b/homa_incoming.c#L935-L1119
set_scheduled_data_priority(homa_state) {
rank = 0; // Just a counter variable.
max_grants = 10; // Hard coded value for maximum grants that can be issued in one function call.
max_scheduled_priority = homa_state->max_sched_prio; // Fixed integer value set using the `unsched_cutoffs` array.
num_grantable_peers = homa_state->num_grantable_peers; // No. of peers in `homa_state->grantable_peers` list.
while(peer in homa_state->grantable_peers) {
rank++;
priority = max_scheduled_priority - (rank - 1); // Calculates the max. priority possible.
/* `extra_levels` is calculated to try to later adjust priority to lowest possible value for SRPT.
* It helps in pushing priorities as low as possible, so that newer higher priority messages can be accommodated easily.
*/
total_levels = max_scheduled_priority + 1;
extra_levels = total_levels - num_grantable_peers;
if (extra_levels >= 0) { // `extra_levels` < 0 implies congestion or too much overcommitment.
priority = priority - extra_levels; // Adjust priority to lowest possible value for SRPT.
}
if (priority < 0) {
priority = 0;
}
// Assign `priority` to `GRANT` packet.
if(rank == max_grants) {
break;
}
}
}
Examples
-
Using the two situations presented in two points below, we can understand how
final_priorityfor every message is assigned in Homa using thepriorityandextra_levelsformulae. -
No. of messages to granted=No. of priority levels(i.e.,6 = 6)max_scheduled_priority = 5 // i.e., 0 to 5, which is six levels num_grantable_peers = 6 rank = 0 // For 1st msg rank = rank + 1 = 0 + 1 = 1 priority = max_scheduled_priority - (rank - 1) = 5 - (1 - 1) = 5 extra_levels = (max_scheduled_priority + 1) - num_grantable_peers = (5 + 1) - 6 = 0 final_priority = priority - extra_levels = 5 - 0 = 5 // For 2nd msg rank = 1 + 1 = 2 priority = 5 - (2 - 1) = 4 extra_levels = (5 + 1) - 6 = 0 final_priority = 4 - 0 = 4 // For 3rd msg final_priority = (5 - (3 - 1)) - ((5 + 1) - 6) = 3 - 0 = 3 // Similarly, for 4th, 5th and 6th (final) messages, priorities will be 2, 1 and 0 respectively. -
No. of messages to granted<No. of priority levels(i.e.,4 < 6)max_scheduled_priority = 5 // i.e., 0 to 5, which is six levels num_grantable_peers = 4 rank = 0 // For 1st msg rank = rank + 1 = 0 + 1 = 1 priority = max_scheduled_priority - (rank - 1) = 5 - (1 - 1) = 5 extra_levels = (max_scheduled_priority + 1) - num_grantable_peers = (5 + 1) - 4 = 2 final_priority = priority - extra_levels = 5 - 2 = 3 // For 2nd msg rank = 1 + 1 = 2 priority = 5 - (2 - 1) = 4 extra_levels = (5 + 1) - 4 = 2 final_priority = 4 - 2 = 2 // For 3rd msg final_priority = (5 - (3 - 1)) - ((5 + 1) - 4) = 3 - 2 = 1 // For 4th (final) message final_priority = (5 - (4 - 1)) - ((5 + 1) - 4) = 2 - 2 = 0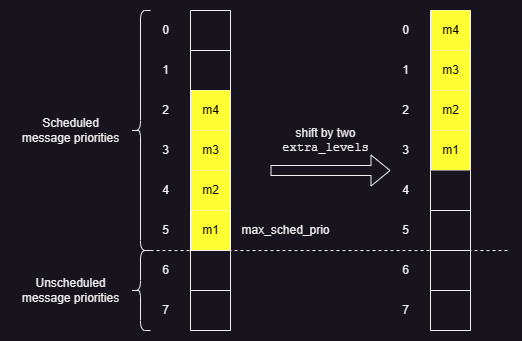
-
From the two situations above, it can be understood that Homa always pushes messages to the lowest possible priorities (using the
extra_levelsparameter) to be able to easily accommodate higher priority messages. -
When
No. of messages to granted>No. of priority levels, then some messages will accumulate at the lowest priority level (0). This can be a sign of congestion and/or too much overcommitment.
Calculating Unscheduled Priorities
unsched_cutoffsis an array of message length values. The length of the array is eight by default.- Each position in the array defines the largest message length that can be used for that priority level.
- The 0th position of the
unsched_cutoffsarray has the lowest priority while the last position in has the highest priority. - Message length values should increase the end of the array to the start of the array.
- This is to implement SRPT, i.e., messages with fewer bytes left get higher priorities.
- The 0th position of the
- A value of
HOMA_MAX_MESSAGE_LENGTHat any position will indicate the lowest priority for unscheduled priorities. All positions below this will be used for scheduled packets.- This array is also used to set the
max_sched_priovariable, as its value will be the array position before the position that has theHOMA_MAX_MESSAGE_LENGTHvalue. - Example: For eight priority levels (
0to7), ifunsched_cutoffs[6] = HOMA_MAX_MESSAGE_LENGTH, thenmax_sched_prio = 5, the scheduled packet priority range is from0to5(both inclusive) and unscheduled packet priorities are6and7.
- This array is also used to set the
- Instead of being a dynamically changing array, this is a statically assigned array in the configuration, at least till commit
9c9a1ffof the Homa Linux kernel module. - When and how is the unscheduled priority used and set?
Unscheduled Priority Setting and Transmission Timing
- Alternate title: ‘
CUTOFFSPacket Transmission Timing’
Initializations
-
Homa initializes priority-based values for the overall Homa state (
homa_state)- Incoming
DATApacketcutoff_versionis checked withhoma_state->cutoff_version.
/* - `HOMA_MAX_PRIORITIES = 8` is a hard coded value. * - `HOMA_MAX_MESSAGE_LENGTH = 1000000` is a hard coded value. * - Code below as seen in https://github.com/PlatformLab/HomaModule/blob/9c9a1ff3cbd018810f9fc11ca404c5d20ed10c3b/homa_utils.c#L104-L119 */ homa_state->num_priorities = HOMA_MAX_PRIORITIES; // = 8 homa_state->max_sched_prio = HOMA_MAX_PRIORITIES - 5; // = 3 (So levels 0 to 3 for scheduled data while levels 4 to 7 for unscheduled data.) // Rationale behind choosing/guessing these values is not clear homa_state->unsched_cutoffs[HOMA_MAX_PRIORITIES-1] = 200; // Level 7 can receive (unscheduled) msgs with <= 200 remaining bytes. homa_state->unsched_cutoffs[HOMA_MAX_PRIORITIES-2] = 2800; // Level 6 can receive (unscheduled) msgs with <= 2,800 remaining bytes. homa_state->unsched_cutoffs[HOMA_MAX_PRIORITIES-3] = 15000; // Level 5 can receive (unscheduled) msgs with <= 15,000 remaining bytes. homa_state->unsched_cutoffs[HOMA_MAX_PRIORITIES-4] = HOMA_MAX_MESSAGE_LENGTH; // Level 4 can receive (unscheduled) msgs with <= 1,000,000 (max acceptable) remaining bytes. homa_state->cutoff_version = 1;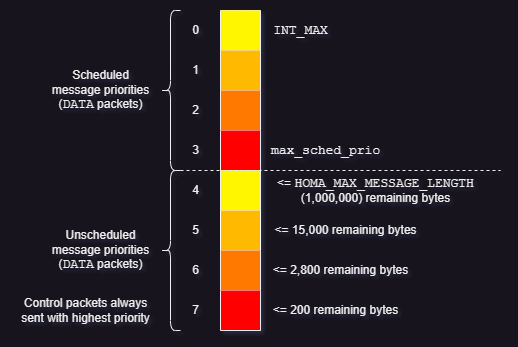
- Incoming
-
Homa initializes priority-based values for every peer whenever it is created
- Outgoing
DATApacketcutoff_versionis added frompeer->cutoff_version.
/* - `HOMA_MAX_PRIORITIES = 8` is a hard coded value. * - Code below as seen in https://github.com/PlatformLab/HomaModule/blob/9c9a1ff3cbd018810f9fc11ca404c5d20ed10c3b/homa_peertab.c#L156-L159 */ peer->unsched_cutoffs[HOMA_MAX_PRIORITIES-1] = 0; // Level 7 can receive no msg data. peer->unsched_cutoffs[HOMA_MAX_PRIORITIES-2] = INT_MAX; // Level 6 will receive all msgs. peer->cutoff_version = 0; // Value `0` implies that no `CUTOFFS` packet has ever been received from the host. peer->last_update_jiffies = 0; // Last `CUTOFFS` packet time - Outgoing
Sender
-
When scheduled or unscheduled
DATApackets need to be sent, the sender assigns priority from the peer data that it has.- If
CUTOFFSpackets haven’t been received for a peer, the defaults for a peer are used as shown above, which might trigger the receiver into sending aCUTOFFSpacket due to thecutoff_versionmismatch.- There is a
cutoff_versionmismatch, as the sender initializes thecutoff_versionwith0(as shown above), while the receiver initializes thecutoff_versionwith1(as shown above).
- There is a
// As seen in https://github.com/PlatformLab/HomaModule/blob/9c9a1ff3cbd018810f9fc11ca404c5d20ed10c3b/homa_outgoing.c#L425-L430 if(rpc->bytes_to_be_sent_offset < rpc->unscheduled_bytes_offset) { priority = get_unscheduled_priority(rpc->total_msg_length); } else { priority = rpc->scheduled_priority; } - If
-
When control packets (packets other than
DATApackets) need to be sent, the sender assigns the highest priority to them.// As seen in https://github.com/PlatformLab/HomaModule/blob/9c9a1ff3cbd018810f9fc11ca404c5d20ed10c3b/homa_outgoing.c#L314 priority = homa_state->total_num_of_priorities - 1;
Receiver
-
On receiving a
DATApacket, the receiver checks thecutoff_versionin the packet for a mismatch with its owncutoff_version(which is the latest, because the receiver drives the sending behaviour of the sender). If the receiver does find a mismatch and if aCUTOFFSpacket has not been sent for a sufficient amount of time, an updatedCUTOFFSpacket is sent.// As seen in https://github.com/PlatformLab/HomaModule/blob/9c9a1ff3cbd018810f9fc11ca404c5d20ed10c3b/homa_incoming.c#L546-L567 if(incoming_pkt_data_header->cutoff_version != homa_state->cutoff_version) { // Implies that the sender has a stale (old) `CUTOFFS` packet. /* Time check (below) in place to not send a `CUTOFFS` packet for every single stale packet, in case a lot of them arrive together. * It helps to pace out the sending of `CUTOFFS` packets. */ if(time_now != peer->last_cutoffs_packet_send_time) { // Send updated `homa_state->unsched_cutoffs` array and `homa_state->cutoff_version` in a `CUTOFFS` packet to peer. // Update time when last `CUTOFFS` packet was sent. } }
Calculating rtt_bytes
- Round-Trip Time (RTT) is the time from when sending a request started to when the receipt of a response for that request completed.
rtt_bytesis the number of bytes of data that can be sent in the time one round-trip takes. Theoretically, if a client keeps sendingrtt_bytesof data, there will be no breaks in transmitting data, which means that link utilization will be 100% and that is the most efficient use of the link’s capacity. (More info)- Instead of being a dynamically changing value, this is a statically assigned configuration value, at least till commit
9c9a1ffof the Homa Linux kernel module. - As mentioned in
9c9a1ff/protocol.md:Note: in networks with nonuniform round-trip times (e.g. most datacenter fabrics),
rtt_bytesshould be calculated on a peer-to-peer basis to reflect the round-trip times between that pair of machines. This feature is not currently implemented: Homa uses a single value ofrtt_bytesfor all peers.
Calculating GRANT Offset
- The most important parts of a
GRANTpacket in Homa are thepriorityandoffsetvalues. - The offset is a value that is smaller than or equal to the length of message to be received. (
offset<=total_length) -
The offset value indicates to a sender that the server is permitting sending all data upto a particular byte of the total message length.
Example: If total_length = 100 and offset = 20, this implies that the server is granting permission to send the first 20 bytes of the 100 byte message.
- The optimal amount of data that should be granted is
rtt_bytes, as that keeps link utilization at 100%. (More info: Calculatingrtt_bytes) - When are offsets and scheduled priorities calculated?
Algorithm
// Logic derived from https://github.com/PlatformLab/HomaModule/blob/9c9a1ff3cbd018810f9fc11ca404c5d20ed10c3b/homa_incoming.c#L935-L1119
set_data_offset(homa_state) {
counter = 0;
max_grants = 10; // Hard coded value for maximum grants that can be issued in one function call.
total_bytes_available_to_grant = homa_state->max_incoming - homa_state->total_incoming;
if(total_bytes_available_to_grant <= 0) {
return;
}
while(peer in homa_state->grantable_peers) {
counter++;
first_rpc_in_peer = get_list_head(peer);
rpc_bytes_received = first_rpc_in_peer->total_msg_length - first_rpc_in_peer->msg_bytes_remaining;
offset = rpc_bytes_received + homa_state->rtt_bytes; // Ensures optimal link utilization
if(offset > first_rpc_in_peer->total_msg_length) {
offset = first_rpc_in_peer->total_msg_length;
}
increment = offset - first_rpc_in_peer->total_incoming_bytes;
if (increment <= 0) {
continue; // No need to grant same amount of data as already expected.
}
if (total_bytes_available_to_grant <= 0) {
break;
}
if (increment > total_bytes_available_to_grant) {
increment = total_bytes_available_to_grant;
offset = first_rpc_in_peer->total_incoming_bytes + increment;
}
first_rpc_in_peer->total_incoming_bytes = offset;
total_bytes_available_to_grant = total_bytes_available_to_grant - increment;
// Assign `offset` to `GRANT` packet.
if(counter == max_grants) {
break;
}
}
}
/* homa_state->max_incoming = homa_state->max_overcommit * homa_state->rtt_bytes;
* `max_overcommit` is the maximum number of messages to which Homa will send grants at any given point in time.
* As seen in https://github.com/PlatformLab/HomaModule/blob/9c9a1ff3cbd018810f9fc11ca404c5d20ed10c3b/homa_incoming.c#L1815
*/
Offset and Scheduled Priority Calculation Timing

- Alternate title: ‘
GRANTPacket Transmission Timing’ - Offsets and scheduled priorities are sent in
GRANTpackets that are created and sent from thehoma_send_grantsfunction. - A
priorityandoffsetvalue to be sent in eachGRANTpacket is calculated for every packet in that same function and added to the packets, just before sending each of thoseGRANTpackets.
The homa_send_grants function is called by
- The
homa_softirqfunction that handles incoming packets at the SoftIRQ level in the Linux Kernel. (SoftIRQ: 1 and 2) - The
homa_remove_from_grantablefunction that removes a RPC from its peer.- This function internally leads to shifting the peer’s position if required, so new
GRANTpackets might have to be sent, which is why thehoma_send_grantsfunction is called. - This function is itself called when a RPC is aborted (
homa_rpc_abort()) or needs to be freed (homa_rpc_free()).
- This function internally leads to shifting the peer’s position if required, so new
Calculating Unscheduled Bytes Offset
- Every message in Homa is split into unscheduled and scheduled bytes on the sender.
- The sender sends all unscheduled bytes of a message blindly to the receiver, i.e., it does not wait for the receiver’s
GRANTpackets to send unscheduled bytes of data. - Scheduled bytes are sent only if the receiver sends
GRANTpackets for a certain amount of that scheduled data. - The split between the two is not even and a certain formula (mentioned in the algorithm below) is used to decide the unscheduled bytes offset.
- It is important to note that Homa calculates an offset for the unscheduled bytes to be sent, so all bytes from the first byte of the message up to the byte indicated by the offset are sent blindly using unscheduled priorities.
- Example: If a message is 100 bytes long and the calculated unscheduled bytes offset is
20, then the sender will blindly send the first 20 bytes of the message to the receiver.
- Example: If a message is 100 bytes long and the calculated unscheduled bytes offset is
- The logic/rationale used to arrive to the formula that calculates that unscheduled bytes offset is not clear to me.
- When is the unscheduled bytes offset calculated for a message?
Algorithm
// Logic derived from https://github.com/PlatformLab/HomaModule/blob/9c9a1ff3cbd018810f9fc11ca404c5d20ed10c3b/homa_outgoing.c#L42-L244
set_unscheduled_byte_offset(rpc) {
/* Network stack layers: Ethernet(IP(Homa(rpc_msg_data_bytes)))
* `mss` = Maximum Segment Size (Max. payload of a Homa `DATA` packet.)
* `mtu` = Maximum Transmission Unit (Max. payload of an Ethernet Frame.)
* `data_header_length` = Length of the header of a Homa `DATA` packet
*/
mss = mtu - ip_header_length - data_header_length;
if(rpc->total_msg_length <= mss) {
// Message fits in a single packet, so no need for Generic Segmentation Offload (GSO).
rpc->unscheduled_bytes = rpc->total_msg_length;
}
else {
gso_pkt_data = pkts_per_gso * mss;
rpc->unscheduled_bytes = rpc->rtt_bytes + gso_pkt_data - 1; // Not clear about the rationale behind this formula.
// Rounding down to a quantized number of packets.
extra_bytes = rpc->unscheduled_bytes % gso_pkt_data;
rpc->unscheduled_bytes = rpc->unscheduled_bytes - extra_bytes;
if (rpc->unscheduled_bytes > rpc->total_msg_length) {
rpc->unscheduled_bytes = rpc->total_msg_length;
}
}
}
Unscheduled Bytes Offset Calculation Timing
- The unscheduled bytes offset is calculated in the
homa_message_out_initfunction, which initializes information for sending a message for a RPC (either request or response) and (possibly) begins transmitting the message, among other things. - The
homa_message_out_initfunction is called by thehoma_sendmsgfunction, which sends a request or response message.- What is weird is that the
homa_sendmsgfunction is not called by any other function and it is not a part of the Homa API as well to be a function that is directly called by a library. (Maybe it is called directly by a library, but I don’t know that and neither is it mentioned anywhere.)
- What is weird is that the
Resources
- Final report (HTML, PDF)
- Directed Study application
- Presentations
- Experimentation instructions
- Research papers
- It’s Time to Replace TCP in the Datacenter (v2) (arXiv)
- Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities (Complete Version) (arXiv)
- A Linux Kernel Implementation of the Homa Transport Protocol (USENIX)
- Datacenter Traffic Control: Understanding Techniques and Tradeoffs (IEEE Xplore)
- The Homa Linux kernel module source
- Videos
- Articles
- Transmission Control Protocol (TCP)
- Remote Procedure Calls (RPCs)
- Incast
- Data Plane Development Kit (DPDK)
- Linux networking specifics